A rectilinear polygon is a simple polygon of which all edges are horizontal or vertical. Let P be a rectilinear polygon with n vertices. Give an example to show that $\left \lfloor n/4 \right \rfloor$ cameras are sometimes necessary to guard it.
The rectilnear polygon would contain $\left \lfloor n/4 \right \rfloor$ parallel “alleys”. At least $\left \lfloor n/4 \right \rfloor$ cameras are needed because no cameras can see more than one alleys.
Let P be a simple polygon with n vertices, which has been partitioned into monotone pieces. Prove that the sum of the number of vertices of the pieces is O(n).
證明一個 n 個節點的簡單多邊形,拆成多個 monotone pieces,節點總數仍然是 O(n)。
n = k + 1 時,T(n + 1) = T(n) + 1 = (n - 2) + 1 = n - 1,
切割的證明為,找到多邊形的最左側點,然後他一定是凸的,將相鄰兩點拉一條線,如果構成的三角形內部沒有其他點,則直接變成 n - 1 個節點的多邊形,如果裡面有點,則挑一個最靠近最左側點的那個點,將最左側那個點與其相連,這時劃分成兩個多邊形,保證算法一樣。
3.11
Give an efficient algorithm to determine whether a polygon P with n vertices is monotone with respect to some line, not necessarily a horizontal or vertical one.
Consider the casting problem in the plane: we are given polygon P and a 2-dimensional mold for it. Describe a linear time algorithm that decides whether P can be removed from the mold by a single translation.
如果不單純派 dy = 1,調用 2DRANDOMIZEDBOUNDLP 判斷是否有解即可,不必最佳化其結果。
4.8
The plane z = 1 can be used to represent all directions of vectors in 3-dimensional space that have a positive z-value. How can we represent all directions of vectors in 3-dimensional space that have a non-negative z-value? And how can we represent the directions of all vectors in 3-dimensional space?
$z = 0 \cup z = 1$
$z = -1 \cup z = 1 \cup x = -1 \cup x = 1 \cup y = -1 \cup y = 1$,有人問說單純 $z = -1 \cup z = 1$ 不就包含了所有方向嗎?但是我思考了一下收斂問題,這之間到底有沒有連續?極限上是相同,但是包不包含呢?這一點我比較擔憂,總之找一個方法將原點包起,保證原點拉到任一個面都能產生出所有方向,我附的答案是六面體,最簡單的四面體都然也可以,但是不太好寫。
4.16
On n parallel railway tracks n trains are going with constant speeds v1, v2, . . . , vn. At time t = 0 the trains are at positions k1, k2, . . . , kn. Give an O(nlogn) algorithm that detects all trains that at some moment in time are leading. To this end, use the algorithm for computing the intersection of half-planes.
公式:$X_{i}(t) = K_{i} + V_{i} * t$
對於所有 polyhedral set $H = {(t, x) : \forall i; X \geq X_{i}(t)}$
The convex hull of a set S is defined to be the intersection of all convex sets that contain S. For the convex hull of a set of points it was indicated that the convex hull is the convex set with smallest perimeter. We want to show that these are equivalent definitions
a. Prove that the intersection of two convex sets is again convex. This implies that the intersection of a finite family of convex sets is convex as well. b. Prove that the smallest perimeter polygon P containing a set of points P is convex. c. Prove that any convex set containing the set of points P contains the smallest perimeter polygon P.
a. 證明兩個凸包交集仍然是凸包 假設凸包分別為 $C1, C2$,題目所求 $C = C1 \bigcap C2$ 已知:A set $K$ is convex if each $u \neq v$, the line-segment $\bar{uv}$ is contained in $K$, $\bar{uv}\subseteq K$ 假設 $C$ 不是凸包,則存在 $\bar{uv} \nsubseteq C$,根據定義 $u, v \in C1, C2$,得到 $\bar{uv} \nsubseteq C1, C2$,矛盾得證 $C$ 一定是凸包。
b. 證明最小周長的多邊形 P 包含所有點集 S 一定是凸包 假設 $P$ 是最小周長的非凸包多邊形,令 $x, y \in P, and \bar{xy} \nsubseteq P$,則 $\bar{xy}$ 會交 $P$ 於至少兩點 $x', y'$,$P'$ 是將 $\bar{x^{'}y^{'}}$ 連起所產生的新多邊形,顯然地 $P'$ 的周長更小。矛盾得證。
c. 證明任何一個凸多邊形 C 包含點集 S 的同時也一定會包含最小周長的多邊形 P。 假設有 vertex $v \in P, but v \notin C$,同時 v 不會在 S 範圍中,因為 C 已經包含了 S。$v1, v2$ 為 $C, P$ 交點,則 $P'$ 是 $v1, v2$ 相連產生的多邊形,則 P’ 藉由 (b) 一定是多邊形,v1 到 v2 的距離更短,找到一個周長更小的多邊形。矛盾得證。
1.3
Let E be an unsorted set of n segments that are the edges of a convex polygon. Describe an O(nlogn) algorithm that computes from E a list containing all vertices of the polygon, sorted in clockwise order.
Algorithm:
得到所有點 ${(x1, y1), (x2, y2), ..., (xn, yn)}$,並且附加是屬於哪兩個邊的端點對點作排序。map< point, vector<seg> > R - O(n log n)
挑最左下的角當作 $(x1, y1)$ 的其中一邊
1
2
3
4
5
6
7
A[0] = (x0, y0) = R.begin().first;
for (int i = 0; i < E.size(); i++) {
for (seg s : R[A[0]]) {
if (s.p0 == A[i] && (i == 0 || s.p1 != A[i-1]))
A[i+1] = s.p1;
}
}
檢查是否為順時針,否則反轉序列 - O(n)
1.8
The O(nlogn) algorithm to compute the convex hull of a set of n points in the plane that was described in this chapter is based on the paradigm of incremental construction: add the points one by one, and update the convex hull after each addition. In this exercise we shall develop an algorithm based on another paradigm, namely divide-and-conquer.
a. Let P1 and P2 be two disjoint convex polygons with n vertices in total. Give an O(n) time algorithm that computes the convex hull of P1 ∪P2. b. Use the algorithm from part a to develop an O(nlogn) time divide-andconquer algorithm to compute the convex hull of a set of n points in the plane.
Let S be a set of n disjoint line segments whose upper endpoints lie on the line y=1 and whose lower endpoints lie on the line y=0. These segments partition the horizontal strip [−∞ : ∞]×[0 : 1] into n+1 regions. Give an O(nlogn) time algorithm to build a binary search tree on the segments in S such that the region containing a query point can be determined in O(logn) time. Also describe the query algorithm in detail.
Let S be a set of n disjoint line segments in the plane, and let p be a point not on any of the line segments of S. We wish to determine all line segments of S that p can see, that is, all line segments of S that contain some point q so that the open segment pq doesn’t intersect any p not visible line segment of S. Give an O(nlogn) time algorithm for this problem that uses a rotating half-line with its endpoint at p.
虛擬化有幾個困難之處,從經濟面向來看,一開始的轉移到虛擬階段和虛擬化的授權費用太高,畢竟不是所有虛擬化的技術都是 open source。從技術層面來看,虛擬化必須針對硬體做銜接,因此有時候必須靠有限的資源進行組合,才能完成虛擬化的單一功能,因此在初步階段,還必須看 Intel 等硬體架構,是否有考慮虛擬化的設計。在現今,已經有根據虛擬化進行設計,虛擬化也更為普及。
Least Recently Used Algorithm (LRU) 以 “最近不常使用的 Page Page” 視為Victim Page。
緣由:LRU製作成本過高
作法:
Second econd Chance ( 二次機會法則 )
Enhance nhance Second Chance ( 加強式二次機會法則 )
有可能退化成 FIFO FIFO,會遇到 Belady 異常情況
Second Chance (二次機會法則) 以 FIFO 法則為基礎,搭配 Reference Bit 使用,參照過兩次以上的 page 將不會被置換出去,除非全部都是參照兩次以上,將會退化成 FIFO。
Enhance Second Chance (加強式二次機會法則) 使用(Reference Bit Bit, Modification Bit Bit) 配對值作為挑選 Victim Page 的依據。對於沒有沒修改的 page 優先被置換,減少置換的成本。
Belady’s anomaly 當 Process 分配到較多的 Frame 數量,有時其 Page Fault Ratio 卻不降反升。
Rank
Algorithm
Suffer from Belady’s anomaly
1
Optimal
no
2
LRU
no
3
Second-chance
yes
4
FIFO
yes
Thrashing(振盪)
當 CPU 效能低時,系統會想引入更多的 process 讓 CPU 盡可能地工作。但當存有太多 process 時,大部分的工作將會花費在 page fault 造成的 Page Replacement,致使 CPU 效率下降,最後造成 CPU 的效能越來越低。
解決方法
[方法 1] 降低 Multiprogramming Degree。
[方法 2] 利用 Page Fault Frequency (Ratio) 控制來防止 Thrashing。
[方法 3] 利用 Working Set Model “預估 ” 各 Process 在不同執行時期所需的頁框數,並依此提供足夠的頁框數,以防止 Thrashing。
作法 OS 設定一個Working Set Window (工作集視窗;Δ) 大小,以Δ 次記憶體存取中,所存取到的不同Page之集合,此一集合稱為 Working Set 。而Working Set中的Process個數,稱為 Working Set Size ( 工作集大小; WSS) 。
Page
Page Size 愈小
缺點
Page fault ratio愈高
Page Table Size愈大
I/O Time (執行整個Process的I/O Time) 愈大
優點
內部碎裂愈小
Total I/O Time (單一Page的Transfer Time) 愈小
Locality愈集中
Fragmentation
分成外部和內部碎裂 External & Internal Fragmentation
Deadlock(死結)
成因
mutual exclusion 資源互斥 一個資源只能分配給一個 process,不能同時分配給多個 process 同時使用。
hold-and-wait 擁有並等待 擁有部分請求的資源,同時等待別的 process 所擁有資源
no preemption 不可搶先 不可搶奪別的 process 已經擁有的資源
circular wait 循環等待 存有循環等待的情況
解決方法
Dead Lock Prevention 不會存有死結成因四條中的任何一條。
Dead Lock Avoidance 對運行的情況做模擬,找一個簡單的算法查看是否有解死結,但這算法可能會導致可解的情況,歸屬在不可解的情況。
Use a. to get: $ \sum Need + \sum Allocation < m + n $
Use c. to get: $ \sum Need_{i} + m < m + n $
Rewrite to get: $ \sum Need_{i} < n $
Dead Lock Detection & Recovery Recovery 成本太高
小問題
Propose two approaches to protect files in a file system. 檔案系統如何保護檔案?請提供兩種方式。
對檔案做加密動作,或者將檔案藏起-不可讀取。
The system will enter deadlock if you cannot find a safe sequence for it, YES or NO? Please draw a diagram to explain your answer. 如果找不到一個安全序列,是否就代表系統進入死結?
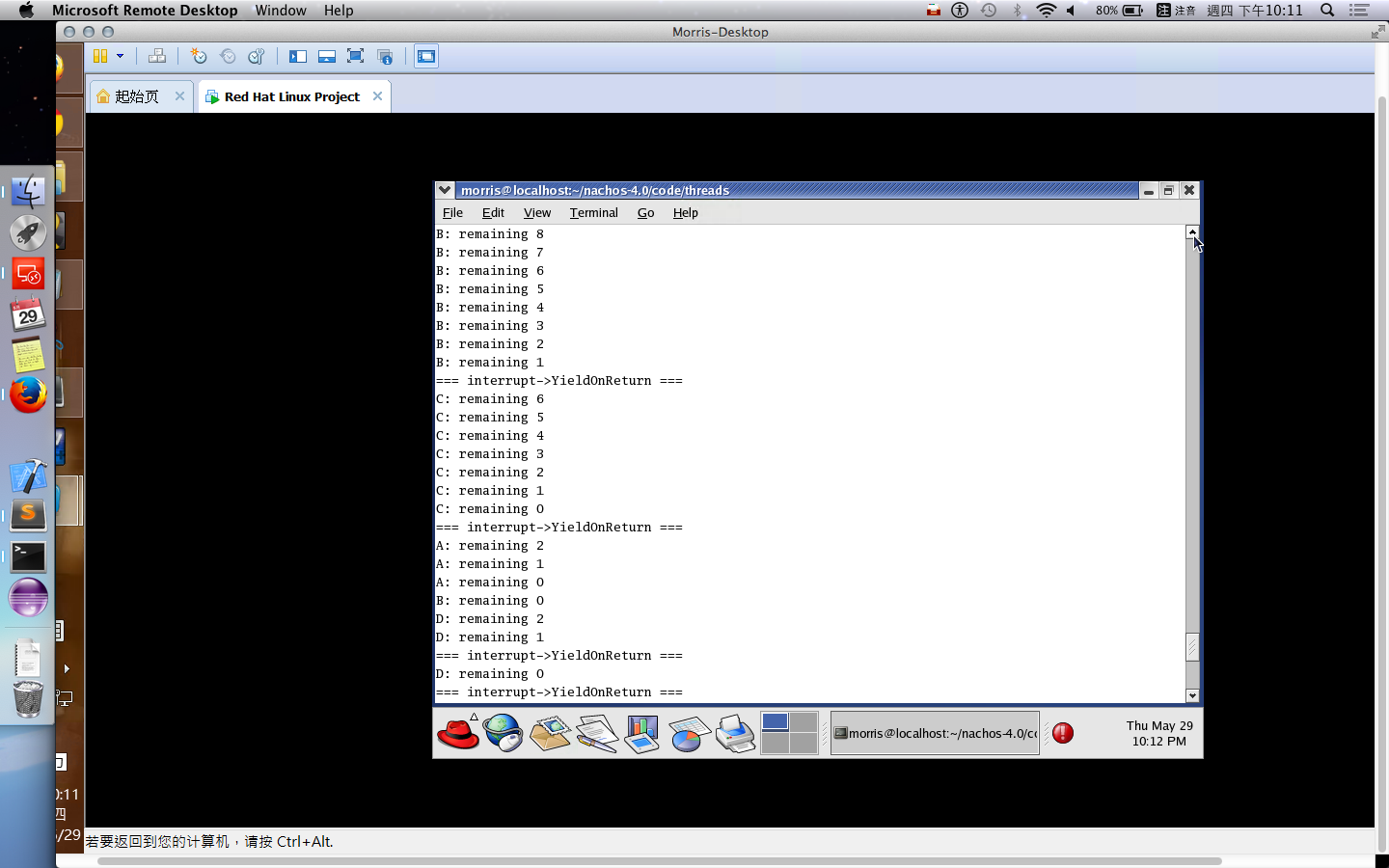
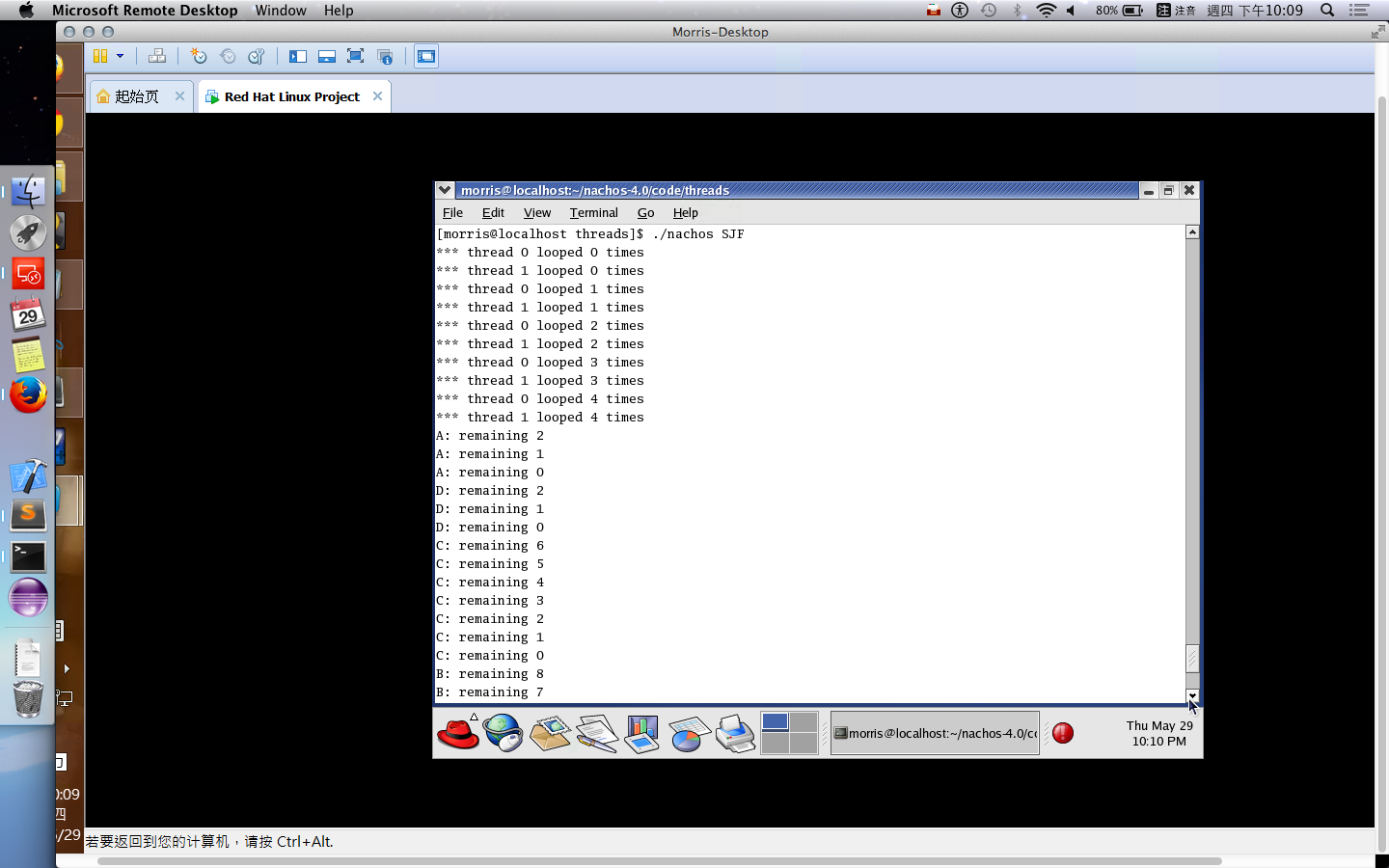
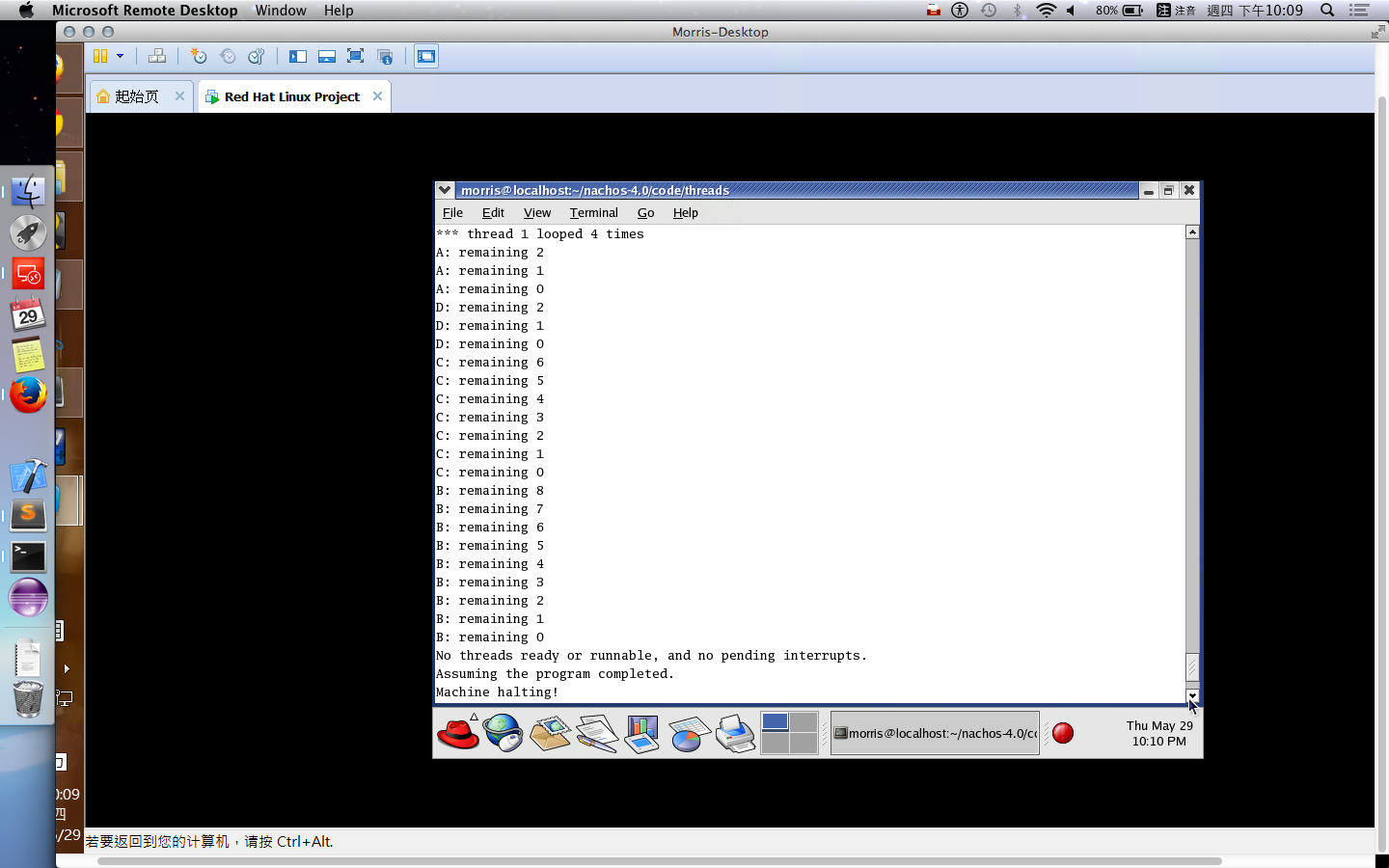
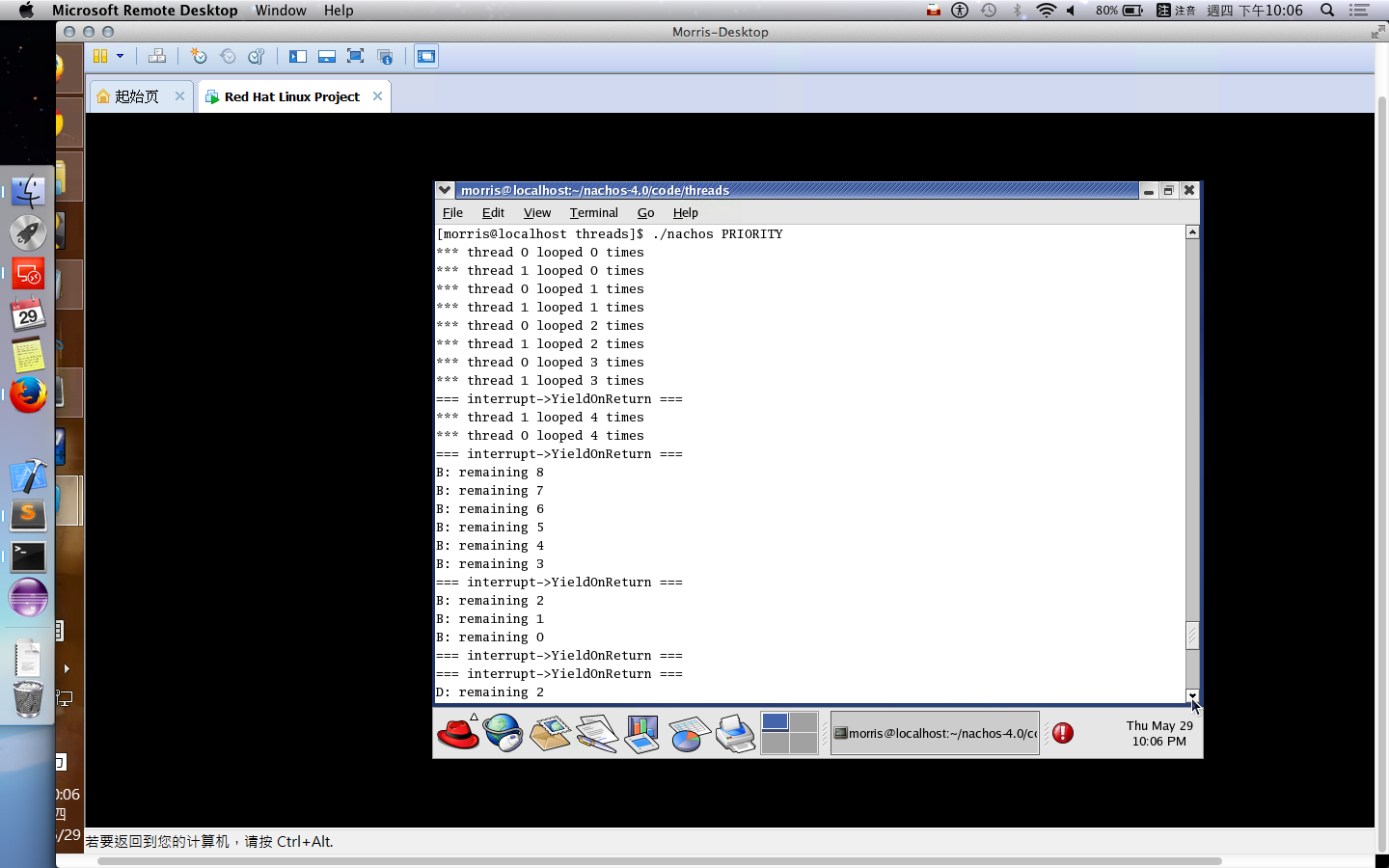
One Exam: 30% 只有一次期中考,而且還是人腦仿電腦考試,但是題目沒有講清楚,考炸了不少,題目理解上把常數搞錯意思,但是這不影響廣義型算法,希望助教給點分!例如:在基因算法中交配的兩兩交配,難道就不能與自己交配嗎?而在粒子算法中,只給兩個參數,難道就不能只模仿全局最佳點和自己嗎?如果只有兩個參數,而且加總為一,您叫我如何模仿鄰居和自己,看來只能二選一。
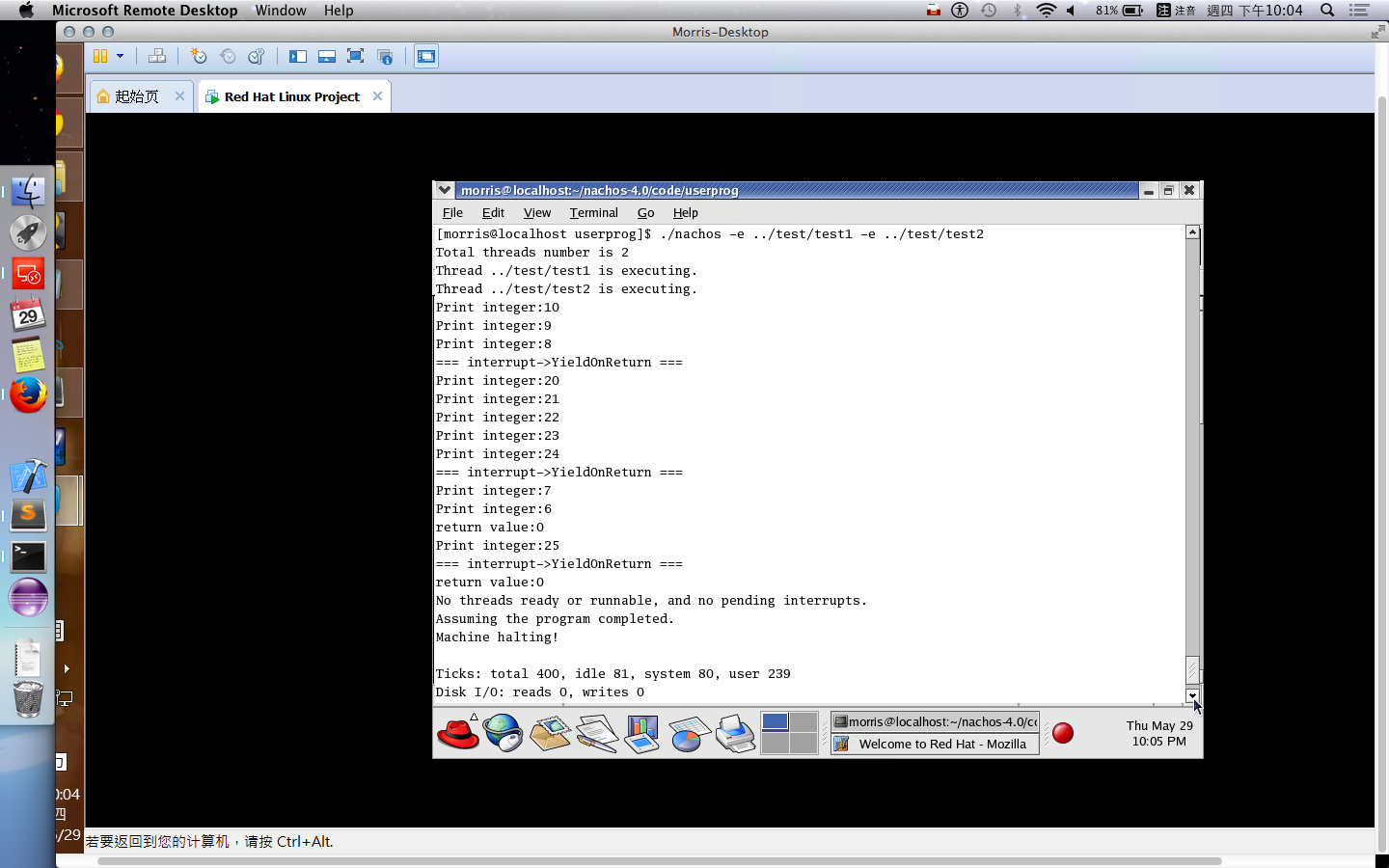
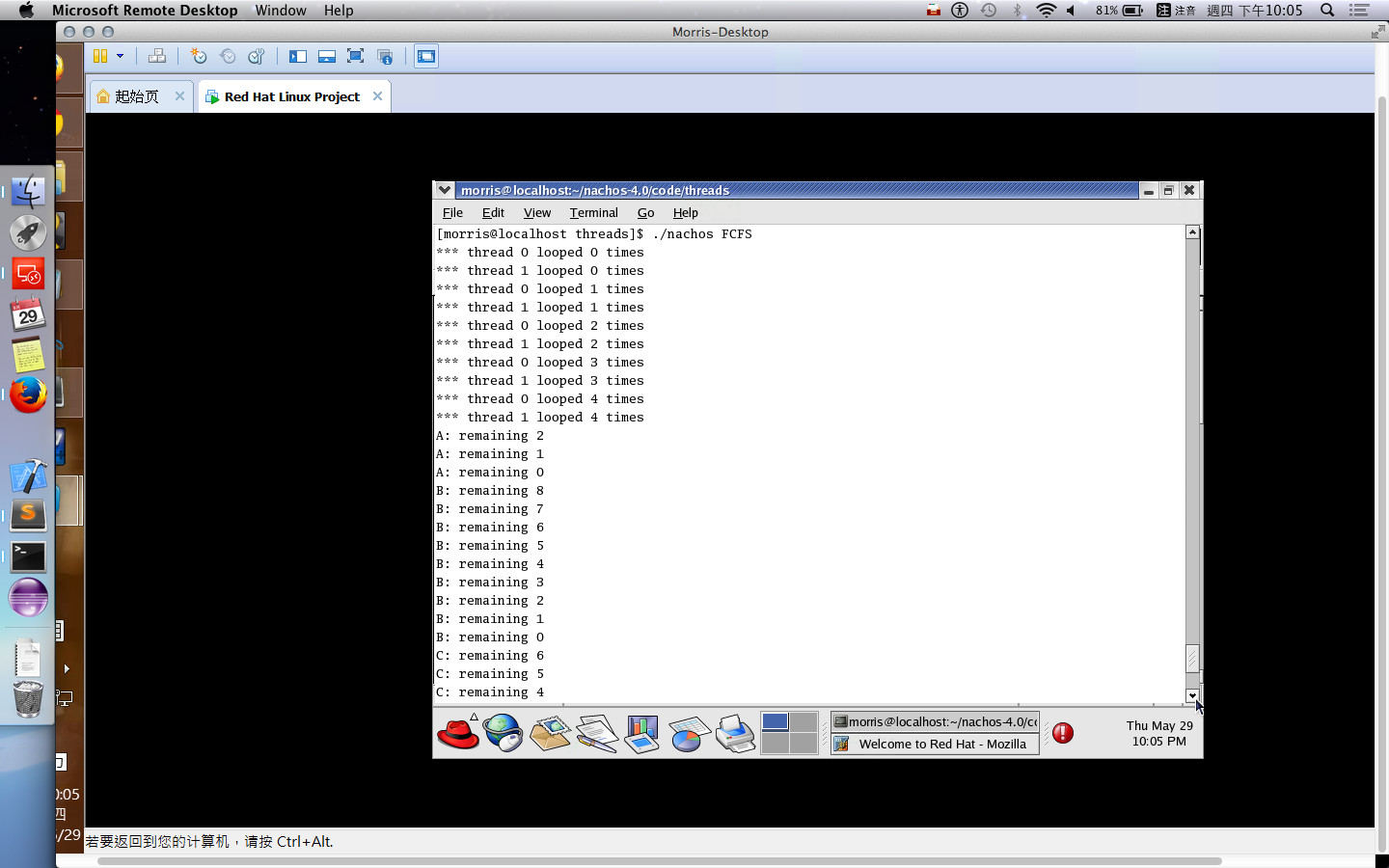
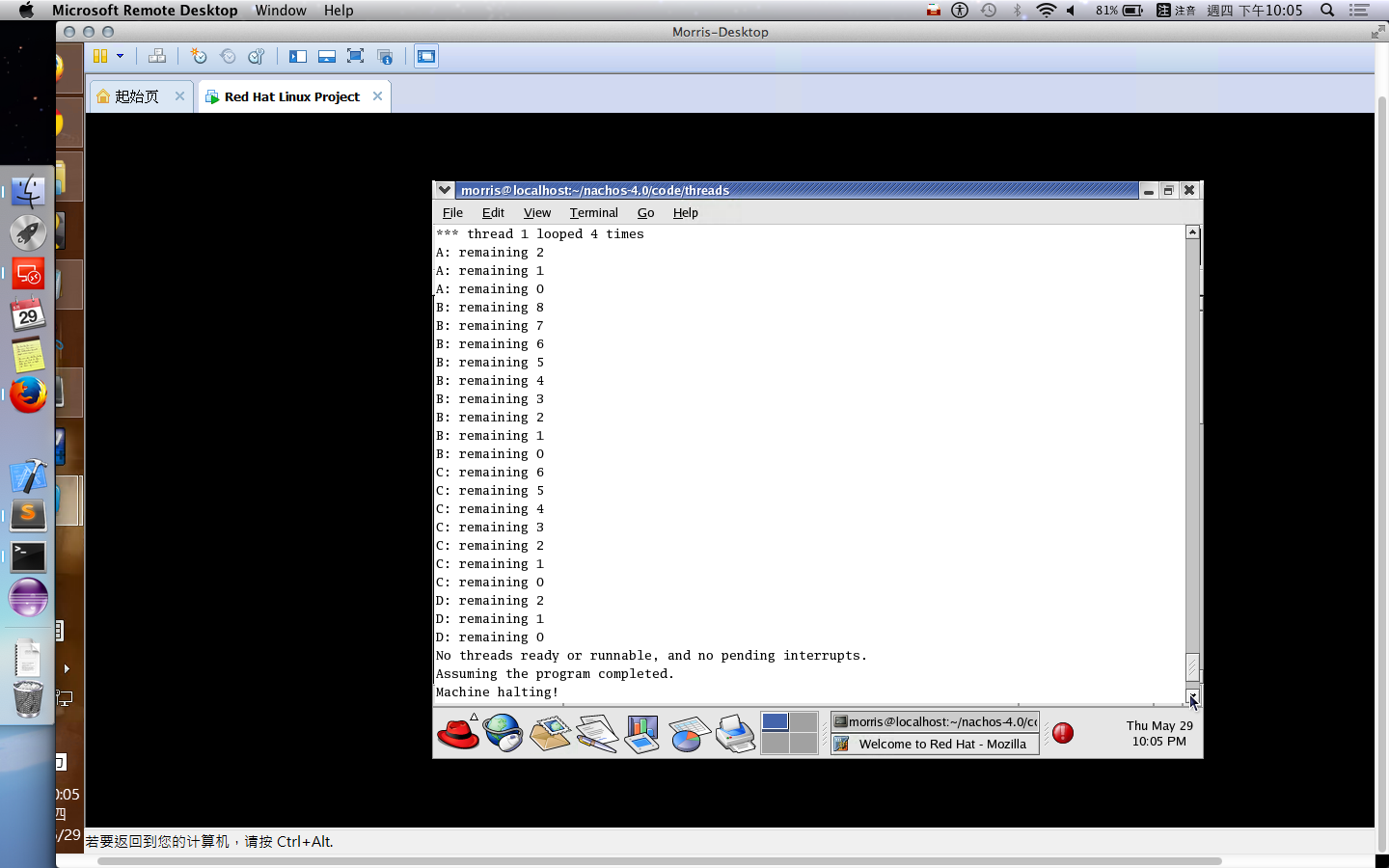
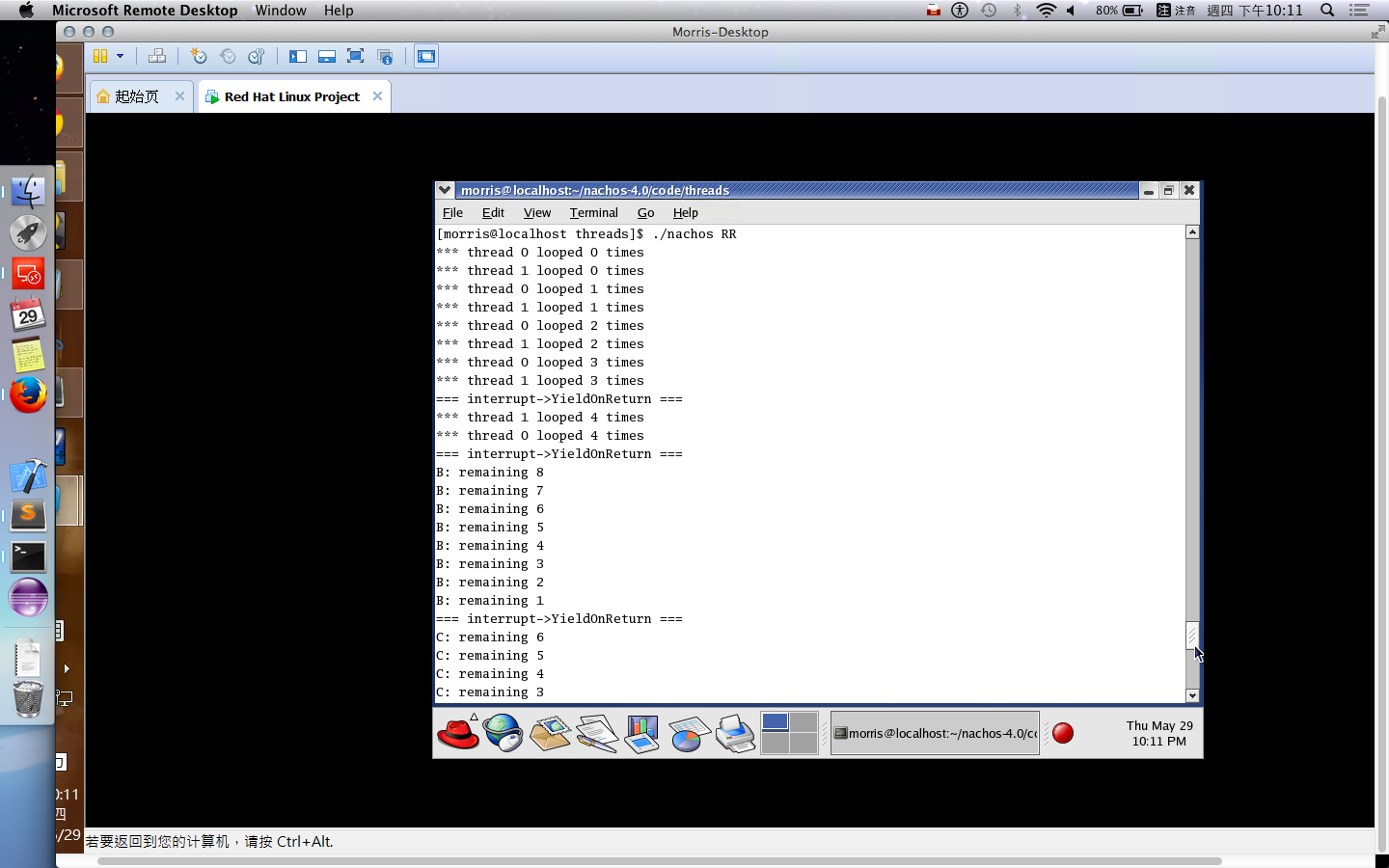
多個為了不增加工作量,這裡就沒有親自去實作。某方面來說,可能要寫很多 small program 進行測試,並且撰寫時還要預測會跑多久,這難度會稍微提高。
第二種方式按照軟工的寫法 來寫 test code 吧!如果細心一點,就會看到相關的 Class::SelfTest() 在很多 class 都有的,因此我們需要把 test code 寫到 SelfTest 中被呼叫。因此,不需要有實體的 process 運行,只是單純地測試我們寫的 scheduler 的排程順序是否正確。
在 Burst Time 計算上,如果採用運行時估計,可以在以下代碼中進行計算。kernel->stats->userTicks 是執行 user program 的時間累加器 (也存有一個 system program 的時間累加器,運行 thread context-free, thread scheduling … 等時間用途。)