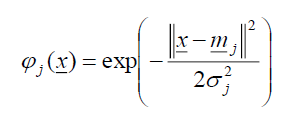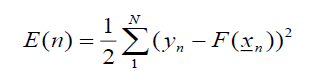課程論文心得
首先,所讀這一篇的論文名稱為『Agile Development and User Experience Design Integration as an Ongoing Achievement in Practice』 所以著重點在于用戶體驗設計要怎麼融入敏捷開發的探討。
什麼是用戶體驗?先說說 UX Designer 做些什麼嗎
第一次轉UX Designer就上手(上)
第一次轉UX Designer就上手(下)
看完內容後,總之 UX Designer 算是一種設計師,與理工背景的開發人員可是天差地遠,
他們比起宅宅開發者來說,要與用戶產生關係,繪畫、表達、心理學、與現實溝通,開發人員擁有技術並且完成目標,但是行為卻不是一般使用者,最簡單的說法是『為什麼做出來的軟體只有開發者會用?』如果在軟體的需求面向是開發者們的話,這也許還不是問題,但是要做出給一般人使用的軟體,這樣是行不同的。但是開發者的邏輯古怪到自己都不明白的機率是挺高的,因此會有 UX Designer。
借由 UX design,軟體將會有耐用性、易上手、輕便化 … 等,這讓我突然想到總是會開發出根本用不著的功能,或者是相當難操作的功能。
但是要把 UX design 完全融入是有困難的,因為邏輯思維不同的人,是很難協調的,又或者會互相侵蝕。
開始談談論文的內容
這一篇論文,主要是 觀察 ,也沒有觀察到所有目前的運行方式。換句話說,不會存在唯一一個好的開發方式,根據組織的規模和文化背景,所適用的運行方式也會有所不同,在理論上百分之百照抄別人的做法運用在自己的發開方式,但是可以藉由論文中觀察的幾點來學習我們的開發方式大概需要的是哪些面向需求。
而當開發人員是怎麼樣類型的人,就可能需要運用哪些方式,這些都是需要去探討的。外國也許按照它們的方式走成功,但並不代表按照一樣的作法一樣會成功,這就所謂 新方法論 。新方法論沒有絕對的方法,說來有點玄,也就是沒有固定方法就是方法!
由於組織規模不同,彼此部門又要互相協調,在設計與開發之間的不同在於時間的週期不同,工作類型的方式不同,如果是大規模組織,『提高內聚力,降低耦合度』因此專業分工的類型將會在 Study 1 中被提及,這麼考量是有它的原因在的。
而文藝復興時期的全才-達文西類型,則可以在 Study 2 中被提及,每一個人都必須學習一點別人的領域的項目,這樣可以互相考量、共同承擔,來分散思考風險。但這樣對於一般人是相當困難的,如果是菁英組織的運行,大概就是長得這樣。
在最後的 Study 3 中,雖然使用傳統的瀑布式開發,這種神祕的設計大於開發組合相當異常,但也許是一種新的導向。在往後的時代中,當技術相對成熟穩定時,面對的將會是設計需求大於開發需求。
RESEARCH METHOD
這裡提供三種 Ethnography (社會學的一種寫作文本,中文翻譯:民族誌) 來探討敏捷開發人員和用戶體驗設計師的配置方式。
A. In the field
(田野調查的區域,民族誌運用田野工作來提供人類社會學的描述研究)
總共有三個組織中,四個團隊參與本次研究,參與研究的團隊中正在進行 UX 設計,而我們主要的工作是觀察他們的工作運行情況。
共計在三種情況進行觀察。
- Study 1: 觀察時間為兩個星期
- Study 2: 觀察時間為六天
- Study 3: 觀察時間為兩天
其中 Study 1, 2 過程中會涵蓋 Sprint 會議,而 Study 3 則只有涵蓋開發人員和設計師共處一室。
B. Thematic analysis
(專題分析)
C. Study participants
(研究參與者)
ACCOUNTS OF THE DAY-TO-DAY INTEGARTION WORK
Study 1
這項研究在 14 位 developer 和 2 位 UX designer,這兩位 UX designer 並不屬於 developer team,而是屬於該公司的 UX design team,因此他們並沒有參與 Sprint meeting、Standup、Retrospective,當然開發人員也沒有參與 design meeting,developer team 和 design team 在不同樓層工作。
開發人員描述道『將 UX design 與 agile develop 分開,是基於管理層面。』這很大的原因在於要將 UX 創造力發揮到極限,不能讓軟體工程的問題阻擋他們思考。
而在 Sprint meeting 中觀察到,UX designer 會提供一個 UX design 在 sprint meeting 前送達。但在隨後的 UX design 版本則是偶爾送到 developer 手上,直到 sprint 的最後一天仍持續修改,這表示著 developer 無法依靠 UX design 考慮相關的實作項目,所以大多數的關於 UX 工作將會分配在最後幾個小時來完成。
然而如果詢問 UX designer 是否已經意識到自己時間分配所造成的影響,則他們會回答說『沒有』。但事實上,在發送 UX design 時就已經造成相當多的問題。
[UX designer]: “That was never explicitly said to me … I thinks there was and still is visibility issues to do with what they’re doing and what their timeline are.”
這表示 UX designer 從來不知道這些事情,也從來沒有直接地被告知這項問題,也是因為不知道 developer 的運行工作和時程表。
當要澄清或者是修改 UX design 時,develop 會將問題寫下,並且要求 UX designer 在他們的 feedback meeting 中討論。
[senior UX designer]: “The visual designs are pretty much parallel to the wireframes … what kind of feedback do you want to give ?”
資深 UX designer 表示道:所有的視覺設計都是在線框 (wireframe) 的基礎上完成的,能有什麼樣的反饋?
developer 並不完全了解 UX design,只能依靠 UX designer 的批准和重構,這 “批准” 主要是對於敏捷開發中的維護和支持的組成用途,但是當 developer 向 designer 發問時,往往是溝通失敗的。
2pm: There is some problem with the visual design from UX [hadn’t arrived yet]. Project manager’s been trying to get in touch with the interaction designer, however can not get in contact - mobile switched off. Project manager has heard that UX are moving desks (not all the visual designs have been delivered since the developer feedback session).
上述內容看得不明白,難道是就是單純 PM 得不到完整的 visual design,因此也就不能向互動工程師聯繫嗎?
Study 2
小型手機軟件開發的公司,這一間公司有兩支團隊,每一隊有 5 名 developer 和 1 名 UX designer。其中 UX designer 設計非功能性描述和 screen mock-ups,這幾個項目將可以幫助 developer 參考進行開發。
mock-ups 相當於一種 prototype 可以支持動作的描述,通常會帶有基礎的 action code,關於 mock-ups 的相關工具有很多,但是通常價格不菲,邊設計還能自動幫忙產生代碼是不容易的工作。網路上找不到相關的解釋,就先這樣頂替了,相較於一般手繪製圖和文件描述,這樣的方式更為容易了解。
在他們會議中,每一個角色(QA, scrum master, product owner, UX designer, developer) 都參與討論會議,創造共同意識和共享決策責任。
9:30 [developer]: How should tabs appear, is ad always right-most tab ? … UX designer tells the developer what whould happen: As new chats come in ad tab moves over to right-most tab.
開發人員: 分頁到底該如何呈現,而廣告要固定在最右側的分頁嗎? … UX designer 告訴我們應該「當新的聊天訊息進來時,廣告要移動到最右邊的分頁嗎?」
[Product owner]: Still waiting on response for some questions from the client.
Product owner: 這仍然在等待顧客的回報訊息
[QA]: Kind of hard to do QA if we don’t have the answer … wayry of starting stories without behaviours which means we might have to change thins and that wastes time.
QA: 這件事情很難做確認,如果我們沒有接收到回報,做的任何修改也許只是浪費時間,無法確定品質。
[UX designer]: Do them anyway, they might need to go through a number of iterations before they agree this is what they want … it’s better of they see something working as soon as posssible.
UX designer: 先把這問題放一旁,這需要多次迭代才能確定這是他們想要的 … 如果他們需要高效工作,則這個方式可能比較好。
[QA]: What if an ad coes in at exactly the same time as a chat ?
QA: 那如果廣告作為一個新的聊天訊息出場的話呢?
[UX designer]: That’s extreme edge case and probably very hard to test. So leave it. QA agrees.
UX designer: 這是一個相當極端的方式,非常難測試,所以先不要管這個。
這些對話通常在每一天的工作中進行,詢問另外一個團隊問題,而另外的團隊注意這些問題。
[UX designer]: “… if developers come up with issues, these are discussed on a case-by-case basis as they come up … There are lots of small things which are easily worked out on a day-to-day basis”
UX designer: 如果 developer 在每一個 case 基礎上想出了問題,這些小問題很容易在每日解決。
從會議過程中,主要,我們可以發現的每一個角色都參與了 UX design,同時也在職權外貢獻了他們的想法 - 例如 UX designer 建議在極端情況忽略 QA testing,而在 QA 沒有指責 UX designer 所做的 QA 決策,他們接受這項意見並沒有發出任何評論。其次,在這個 UX design 討論議題中也一起討論了 non-UX 的問題(如這個 QA testing 問題)。
這次的會議的下一步行動,包括實現解決方案和傳達問題給客戶。所有的角色參與討論導致決策同時考慮的設計價值和技術考量。
而在會議中,有 developer 向其他人簡單說明,他在網路空間上有一些之前專案製作時替換視覺設計的文件可以參考,這可以讓 UI designer 可以接受這些更改的項目,增加信服力。
[UX designer]: Sometimes the developers’ decisions are better, as they are much closer to the implementation. 有時候開發者的決策會更好,因為他們更接近實作。
Study 3
在非常小的公司進行,有 1 名 developer 和 2 名 UX designer,他們擅長瀑布形式的開發,在開發過程中 developer 和 UX designer 在同一間辦公室工作,目標是使得設計和開發更接近。正如 Study 1 的時候,發現 developer 會根據 UX designer 設計的線框 (wireframe) 和 visual design 努力地工作。
觀察兩天後的結果如下:
在一般的情況下,UX designer 通常和 developer 在不同樓層工作,developer 也表示他們很少去找 designer 討論遭遇的問題。
[developer]: We often find things that don’t work, but we don’t go back to design. We just do our best. 我們常發現很多事情並不會 work,但是並沒有回去檢討設計,單純盡力而為。
在這種共同工作的情況下,designer 給予了一些回應。
[UX designer]: This style of working means we can collaborate in order to get our points across, rather than dictate because there’s no communication going on. 這種工作方式可以讓我們的觀點交換,而不是因為沒有通通合作的命令。
[Head of UX]: And when we first met with the client, the first thing they did was to present to us the findings of that initial research. So we can then go and propose what would bee the next step, which is quite different from any other type of work we’ve been invited to get involved in.
在大多數的情況,不確定性,設計師在現場談話的記錄:
[visual designer]: I just feel like I’m not getting any-where.
[IA]: I also feel that way.
但是對於另一個情況下
[developer]: Just cover the site map.
developer 和 designer 共同工作
- 可以相互討論跟顧客對談時的內容 (當時在場的感受不同)
- 目標計劃做些什麼,訊息可以提前知道。(想要做第二個版本)
- 「這個設計會不會很難實作?」這些問題將會很快被反應出來。
[developer]: It would probably be just as easy.
THEME FOR ACHIEVING INTEGRATION
A. Integration as expectations about acceptable behaviour
在 Study 1 中可以發現,如果將兩者隔離,很容易造成規劃的浪費和開發者在最後期限前超時工作。UX designer 同時跨越多個專案進行設計,丟出設計之後就沒有可接收開發者的反饋,只有等到 sprint meeting 的反應才重新設計,這時可能已經為期已晚。
在 Study 2 中可以發現,頻繁確保兩者之間有相互支持,並且在 UX design 和代碼之間可以互相溝通,相較于 Study 1 上,溝通性有上升,但這些遭遇的問題將會在每個人參與討論會議的過程中的一部份。
在 Study 3 中,每一個成員都有機會被其他角色問到自己領域的問題,同時也可以在與客戶討論中的觀察,在隨後討論。這都歸因于他們在同一間辦公室工作。
B. Integration as mutual awareness
相對于 Study 1 中,Study 2, 3 擁有了共同享有決策的責任,同時提高了互動上的認識。